Continuous Integration(CI)/Continuous Delivery(CD) Strategy
This page aims to lay out our strategy for CI/CD pipelines across our projects. There is
additional guidance for developers detailing the process for deploying code changes.
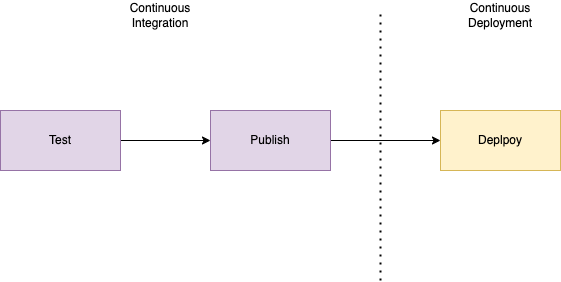
We have simplified it down to three key steps:
- Test - this is where code is tested, all repositories containing code should have this step!
- Publish - this is where code is built and released. It’s important to remember that at this point code has not been deployed into our infrastructure.
- Deploy - In this diagram we keep this as a single step but it may be mmultiple depending on the code being deployed. this step is inn charge of automatically deploying code once it was been published. It is handled in AWS and may not be neccessary for certain repositories.
It’s worth noting that this strategy is fairly generic so we can apply it across a mixture
of code bases including:
- Applications
- Code libraries/packages
- Data Pipeline Tasks
Continuous Integration (CI)
Our CI is handled inside of github using github actions on each repository. Any secrets
are stored in environments for that repository and are managed in AWS and terraform is used
to create and assign them to that repository
Test:
- sets up a test environment inside of a github task runner
- at the minimum should run unit, integration and acceptance tests
- reports should be generated and displayed against the action.
- will be very specific to each repo.
There MUST be a test workflow inside every repo. - If this isn’t present it’s a good indication that the code isn’t being tests.
This action must:
- run automatically on all branches except the main branch. This ensures that code is tested before being removed
- have a manual workflow trigger so it can be manually ran on any branch.
- Both lint and test the code
A template for this is as follows:
name: Test
on:
push:
branches-ignore: [main]
workflow_dispatch:
jobs:
test-code:
runs-on: ubuntu-22.04
steps:
...
...
The specific steps will differ based on what code is being tested. In the long term we hope to create some generalised actions which can be used across our repos.
Publish:
The publish step varies on it’s scope depending on what the code is.
- should publish a version of the code in a given format which can be used
by our infrastructure. there should be a way to publish the code for each of our environments - development needs to be able to be triggered separately.
- Staging and production should be published when merging into the main branch
- should be ran after testing is complete
- For applications - This will be a docker image that is generated inside of
a task runner. Using secrets it is then published to the AWS docker repositories
for the environment which the publish action is being triggered for. The required secrets
will be provided by the Devops team in the repos environments. - For Data engineering tasks - the same as applications for docker images (the difference is in the CD)
For other aspects it may be more specific. E.g. airflow dags are pushed to an s3 container
and lambda functions will be compiled and uploaded as a zip. - For Code libraries - we haven’t got a system
set up but it will likely use git tags to publish the code to a tag. Digital-land-python is the main code library we maintain for data processing
There SHOULD be a publish workflow inside every repo - this may not allways be necessary right now as we don’t publish our code libaries but one day…
The Publish workflow MUST:
- RUN THE TESTS AGAIN! - this is done primarily to ensure code is tested before publishing incase of dependency changes.
- run automatically on the main branch. If it publishes to environments then it should publish to all environments on a push to the main brnach
- have a manual wokflow trigger which can be applied to have branch. If it uses environments then the environment being pushed to should
A template for this is as follows:
name: Publish
on:
push:
branches: [main]
workflow_dispatch:
inputs:
environment:
type: environment
description: The environment to deploy to.
jobs:
test-code:
runs-on: ubuntu-22.04
steps:
...
...
build-and-release-container:
runs-on: ubuntu-22.04
steps:
...
...
Continuous Deployment
This is more complicated and is handled entirely within the AWS environment. It is also very dependent on the type of code that has been published in CI.
For Applications
This is replicated inside each of our staging environments and developers have control over which ones they can publish containers to. The process goes as follows:
- Applications are published as Container images into an ECR repository.
- This automatically tells AWS code deploy to begin a new deployment
- AWS CodeDeploy uses a blue/green deployment to deploy a new version of the app
- AWS Code Deploy will remove all of the old containers once all health checks have passed and traffic has been successfully rerouted without any issues being raised in the containers.
Notifications of the above will be posted into the platform slack channel as it proceeds through the various steps. if there are any issues then reach out to the DevOps team
For Applications our CD MUST:
- Deploy the new application automatically
- Roll back the deployment if any health checks fail
- Remove the old applications
For Data engineering
It works a bit differently for data engineering tasks. CI in github will handle publishing the code ,for example a docker container, but this will not cause AWS to automatically run a data engineering task.
Instead upon the container being published, AWS will automatically update any task definition that uses the container. So when a task is the most updated to date container is used.
This can vary a lot between different types of data engineering tasks but essentially CD will ensure that any new code is ready to use but to action it a data engineering task will need to be triggered.
For Data Engineering CD MUST:
- ensure tasks/processes are automatically updated so they are ran when they’re next triggered
For Code Libraries
For code libraries we don’t support any specific CD. It is up to the relevant application or task to use the library as needed. For example:
- An application is compiled in an image with the code so it will need to be re-deployed using it’s CI/CD pipeline to utilise and changes in the libraries it depends on
- A data engineering task which is a pre compiled lambda function will need redeploying
- A data engineering task which updates a python library each time it’s run will not need redeploying.
For Code Libraries our CD does not have any strict requirements!