Data Architecture
Our key product is to produce a data platform which is capable of serving consumers with data related to the planning system. Because of this we have to perform a lot of processing to retrieve data from data providers and get it into the correct format.
Overview
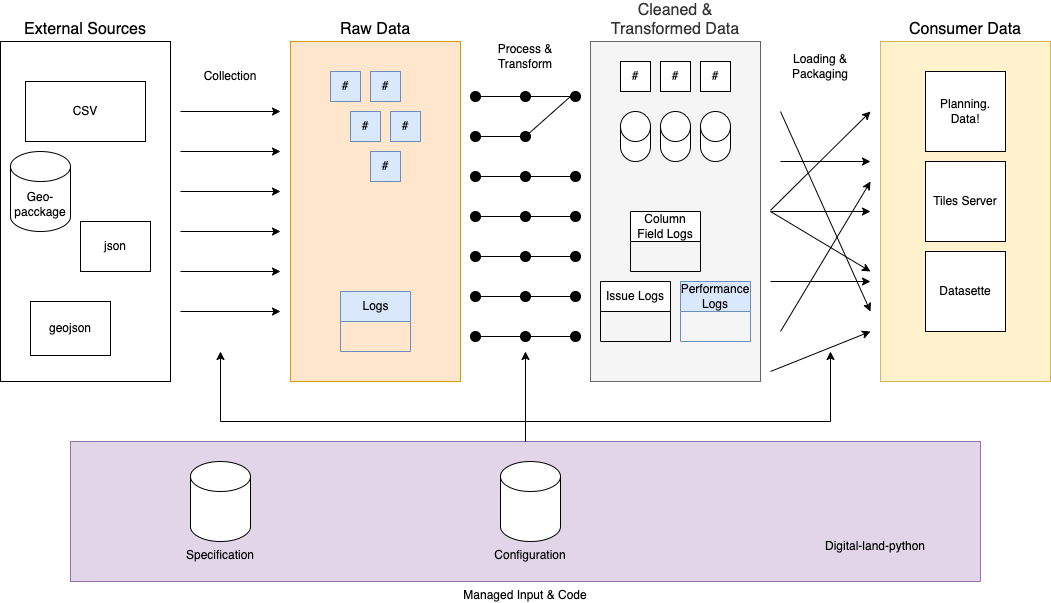
The above diagram gives an overview of what our pipelines are aiming to achieve, that is to extract data from data providers, process this data according to our specification and deliver it in whatever form is required by the consumer. The key elements of the above diagram:
- Data Layers
- Data Processes
- Inputs
This diagram does not describe how we implement this functionality through cloud infrastructure, these can be seen by the solution design section. The implementation is separate from the Data Architecture and can be changed, we will link through below. The solutions design also describes in more detail application and other technology which we use rather than how the data flows through the system.
Data Layers
- External Sources - these are individual endpoints which are available publicly on the internet. We can take a wide range of sources and we can possibly expand in the future
- Raw Data - the data that we have downloaded from external sources and the logs that are relevant to this process. This is incredibly important as if we lose either of these it’ll be hard to get it back and we wouldn’t accurately be able to describe the history of our data.
- Cleaned & Transformed Data - As the name suggests this is the data after we have cleaned and transformed it into the relevant formats. This is the widest layer as there are multiple steps which can take place. The aim is to have data which can easily be loaded into the consumer layer. The data may also already be consumable at this point.
- Consumer Data - This is the data in whatever format is best to be downloaded and consumed by those people using our platform. Not all data being consumed has to be in this layer, this describes any additional loading steps that have had to be taken to get the data to consumers. E.g. creating a tile server or loading it into our postgres database.
Data Processes
- Collection - Collection has a couple of meanings in our project, in this context it’s describing how, when and what data we are pulling from external sources. The sources are passed through from the inputs.
- Process & Transform - This happens after the data has been downloaded, the process aims to utilise inputs to take raw data of varied shapes and turn it into our predefined schemas. At the end of this we should have views for each individual dataset.
- Loading & Packaging - these are specific processes which get the data to where it needs to be. It also does some additional packaging to combine data from multiple datasets.
Inputs
- Specification - this can be viewed in the specification repo and in itself is a data model of data models. It dictates the scope of our project and what the shape of both the expected input of data (although the config allows us to be flexible on this) and the shape of the outputted data on our platform. This is owned primarily by the service owner and the data design team.
- Configuration - this allows the data management team to describe how data should be processed across the various stages and is owned by that team. This includes what endpoints to download data from, all the way through to what special transformations and tests should be done on the data.
- Digitall-land-python (Code) - this is the implementation of both the specification and the configuration. It is what is actually happening when various inputs are supplied and is designed to fulfil the needs of the other teams of the pipeline. It is owned by the infrastructure team. It is worth noting that this allows us to run the same processes in almost the same way across different infrastructure implementations as it is a python library containing the capabilities of the different data processes.
Implementation
As hinted at above the concepts can be implemented in various different ways. We may want to run the process differently in the cloud making use of more scalable solutions than locally. Or some tools may require the capabilities on demand rather than in a big batch process. The aim is to write flexible code in digital-land-python which we can utilise in different scenarios.
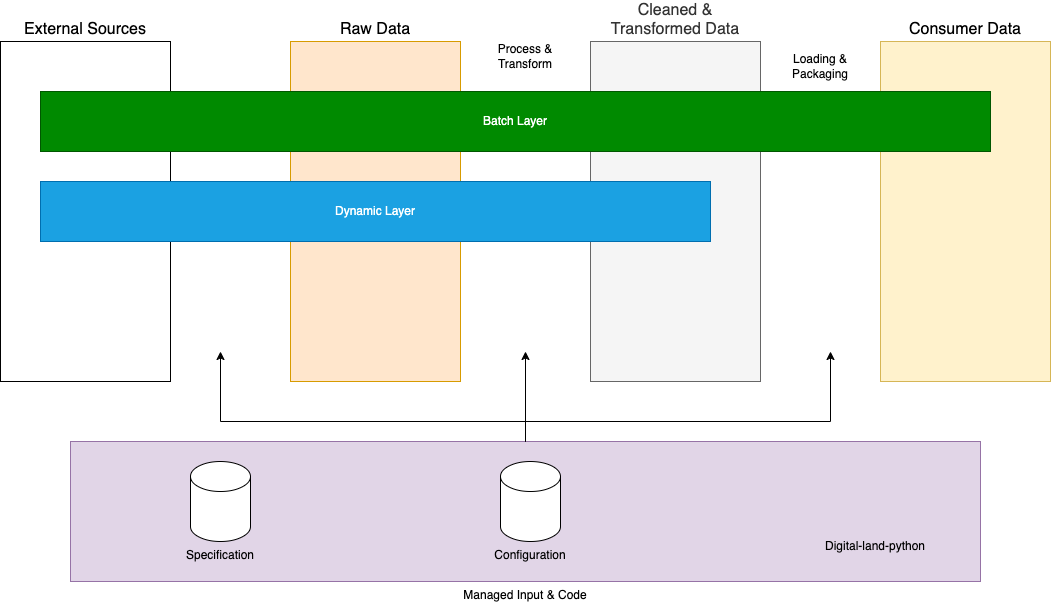
There are currently two main different implementations:
- Batch - this is how data gets on the platform, each night these processes are ran to update all of the data on the platform. This is implemented using airflow as a workflow orchestrator. This is scheduled to run each night but these processes can be manually triggered by a member of the team during the day.
- Dynamic - this was developed to support the checking of data outside of the primary pipelines. It isn’t intended to load data into the platform and instead replicate aspects of it to get faster results. There are possible applications for the configuration manager tool. It is accessed via an api and uses celery and SQS to que and trigger tasks as required. As from the above diagram it’s worth noting that this layer is a lot more limited in what it can achieve.