Our data standards design process
Colm Britton — 2024-01-15
Recently we’ve been developing and refining our data standards design process. We’ve been working on the process to make it more repeatable and modular.
Having a more repeatable process helps us produce better and more consistent results. It will also make it easier to open up our process for others to follow.
Having a more modular process makes it easier to track and share progress. It also makes it easier to see where things are getting stuck, which we can then investigate and make targeted interventions.
This process isn’t the final process, we will continue to refine and improve it as we learn more.
Each planning consideration we take through the process gives us more information. Measuring what worked, what didn’t work and what needs tweaking helps us make each step more efficient.
Our process
We’ve broken our process down into stages. Using these stages improves the visibility of our progress. We want to make it easy to see which stage a planning consideration is in as it goes through our process. We also want it to be easier to identify where things are getting stuck.
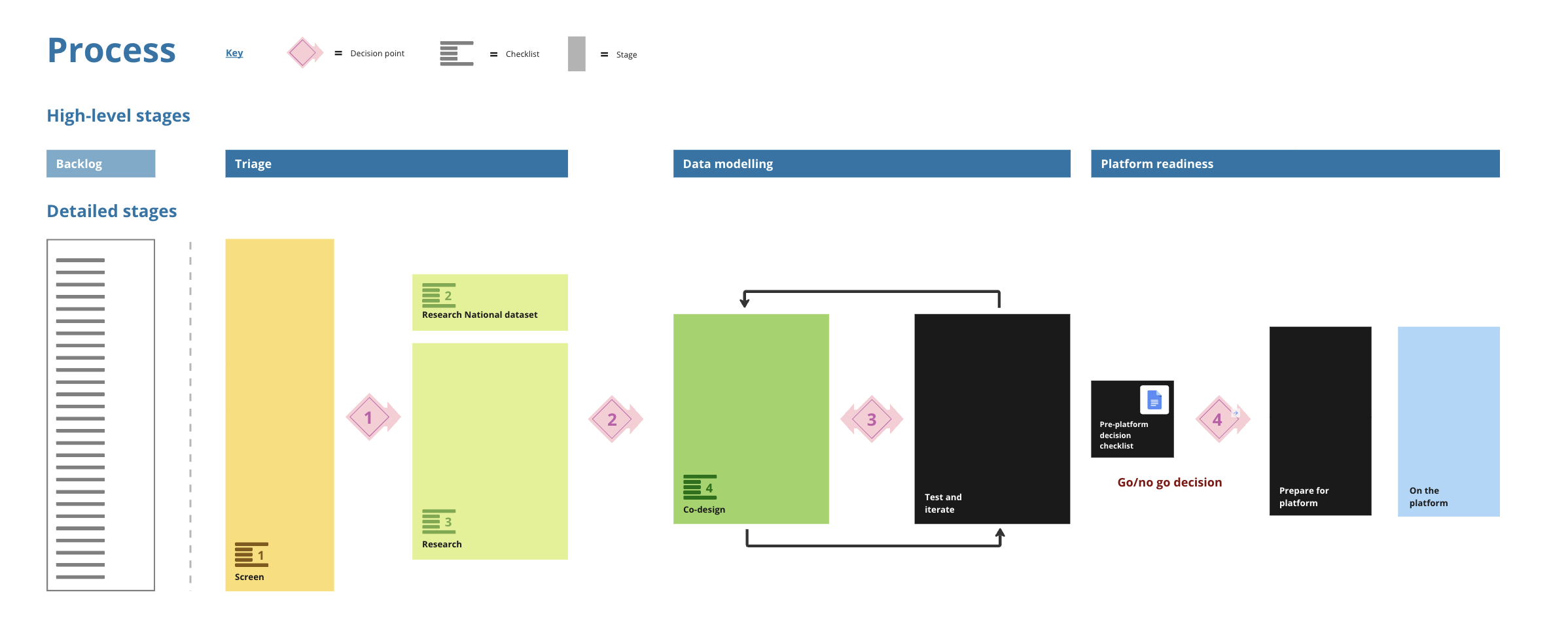
The stages of our process are:
Backlog
Our backlog is a list of things that might be useful to the planning system if they were recorded as data. It’s a broad list and contains things from lots of different sources. We welcome any suggestions. If it is on the list we’ll at least consider whether it is something we should explore further. At this stage, we often only know the name and who told us it was worth looking at.
Screening
We take a high-level look at the planning consideration at this stage. We are trying to work out if it is a real thing, has legislation to support it and whether there is a clear need for it. At this stage, it is usually possible to tell if we can use an existing national dataset or whether a standard might be needed.
Researching
We dig into the planning consideration in greater detail at this stage. Here we are trying to understand what the planning consideration is used for, how it is ‘created’ and how different users interact with it. We are trying to gather enough information to know whether we can and should start modelling the data.
Co-designing
We design a data model at this stage. We create the minimal data model that satisfies the user needs we have previously uncovered. We then work with stakeholders and the community to check we are on the right track and to define the supporting code lists - for example planning-application-types. At this stage we also test the model using sample data.
Test and iterate
At this stage we take the data model and test it with real data created by data publishers. What we learn from this testing feeds into changes and tweaks to the data model.
Go/no-go decision
At this stage, we summarise what we’ve learned so far, highlight why we think this data is valuable, call out any potential risks when making the data available, and take this to our governance board. This stage gives us the opportunity to check we have done everything we need to do and whether this is data we should be adding to planning.data.gov.uk
Prepared for platform
If we get the go-ahead we then need to prepare some materials for the platform operations team. This helps them to get the data onto the platform in the correct format without any issues. These things include schemas, entity ranges and configuration files.
On the platform
Once the platform collects the first batch of data we check it’s structured as we expect. Any available data can now be used.
What happens next
The work doesn’t stop once the platform starts collecting the data. For compiled datasets (datasets we compile from multiple sources, such as conservation areas from 300+ local planning authorities), the platform team stagger the rollout, collecting data from a handful of local planning authorities at a time.
During this period we usually say we are ‘piloting’ the standard. Piloting is a chance for us to collect more feedback from data publishers and where necessary change the standard before it becomes more widely adopted.
You can see the standards we are piloting on our website, as well as the standards that have progressed to candidate or open status.
We hope that gives you a better understanding of how we design data standards.
Over the coming weeks and months we’ll share more details about what goes into each stage, as well as sharing more details about the lifecycle of a data standard.
We’d love to know what you think. Do the stages make sense? Have we missed something? Do you have any questions?