How we store data from local planning authorities and keep it up to date
Greg Slater — 2024-08-14
The planning data platform collects data from a diverse range of sources. How we store and manage this data once it’s been collected is fundamental to our vision of making land and housing data easier to find, use and trust.
The data model used by the platform is based on the concept of a named graph. This means that we can create globally unique identifiers (URIs) for the things that we hold information about. For example, this Article 4 direction area in Barnet can be identified as: https://www.planning.data.gov.uk/entity/7010002551. We refer to this Article 4 direction area as an “entity”, i.e. a distinct thing. Each distinct thing we hold data about is its own entity with its own unique identifier, and each entity essentially acts as a container for all the pieces of information we gather about it.
This model has advantages:
- We can use a single data model to store data from a huge range of different sources, and about lots of different things
- We can combine data from different providers who publish information about the same things
- We can keep a record of the provenance for all the pieces of data we collect
This provides benefits for our users:
- They can access a huge range of data using consistent methods, whether they’re interested in tree preservation zones in Southwark, or public transport access nodes in Bolton
- They can always interrogate the provenance of the data they’re interested in, helping to improve their trust in it
- They can use a unique and persistent identifier to make reliable references to the same thing across different systems, for example, from our platform to planning services like PlanX
Let’s run through how we collect open data published by a local planning authority to create an entity on our platform, explaining the model that we use to store this data throughout that process. We’ll use the Barnet Article 4 direction area entity as an example to follow the process from beginning to end.
Endpoint and resources
We ask local planning authorities to publish open data on their website using a publicly accessible URL, which we refer to as an “endpoint”. Once an endpoint is added to our data processing pipeline it will be checked each night for the latest data. When an endpoint is added for the first time we take a copy of the data; this unique copy is referred to as a “resource”. If the pipeline detects any changes in the data, no matter how small, we save a new version of the entire dataset, saving this copy as a new resource. Each separate resource gets given a unique reference which we can use to identify it.
This URL is the endpoint Barnet have provided for their Article 4 direction area data:
https://open.barnet.gov.uk/download/e5l77/dhv/article4-direction-areas.csv
You can follow the link yourself to see the CSV file that Barnet have used to share their data.
This query in datasette – a tool we use to explore the datasets produced by our pipeline – shows the IDs for each of the resources which have been collected from this endpoint, each a unique hash code with a start-date and end-date which record when the resource was first collected (start-date), and when it was superseded by a new resource (end-date). The most recently collected resource has no end-date, as hasn’t yet been replaced by any new data.
Resources and facts
Each resource contains a lot of data, and we record this data in a way which means we build up a record of all the information that has ever appeared on an endpoint, as well as tracking when it appeared. This provides a valuable record of any changes made to the data.
The data from each resource is saved as a series of “facts”. If we imagine a resource as a table of data, like the CSV file from Barnet, then each combination of entry (row) and field (column) generates a separate fact: a record of the value for that entry and field.
Using Barnet’s article 4 direction area endpoint from above as an example, here is how the first two rows look for the reference and name fields:
| reference | name |
|---|---|
| A4D1A1 | Article 4(2) for Finchley Church End CA Area 1 |
| A4D1A2 | Article 4(2) for Finchley Church End CA Area 2 |
This snippet of the full table contains 2 entries and 2 fields, meaning there are a total of 4 facts. Each fact gets given a unique identifier in the same way the resource does. You can see how these facts appear in our data.
So a table with 10 rows and 10 columns would generate 100 facts. And each time data changes on an endpoint, all of the facts from the new resource are recorded again. We can use these records to trace back through the history of data from an endpoint.
Entities
Entities are important as they’re the things that actually end up being displayed on the website, in maps, and in planning services using our data. We create new entities when we add an endpoint for the first time, usually creating one for each unique record in a resource. We ask that data providers share data with a unique reference field so that we can record the relationship between our entity numbers and the reference that the data provider uses to refer to that entity.
Once that record of the relationship between the data provider, their reference value, and our entity number is created, the entity will hold all of the facts from entries with that same reference value that have ever been generated from relevant resources. The value displayed for each field on the web page for an entity is always from the most recently updated fact.
Using our example Barnet Article 4 direction area entity we can see the information we’ve captured as facts represented on the entity web page.
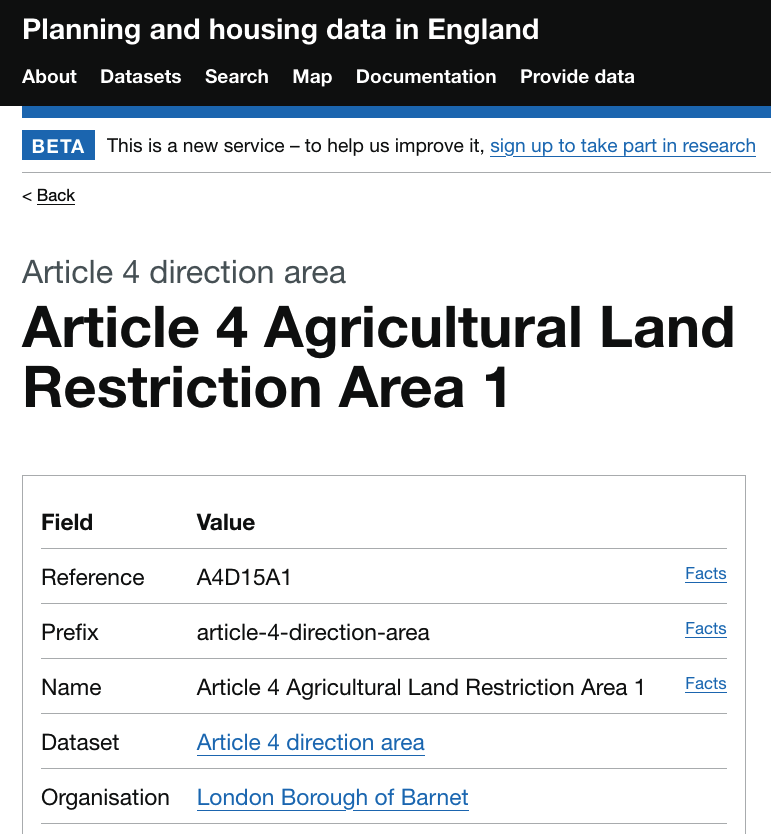
The Facts links on the right allow users to explore the provenance of each field and value through the facts that we’ve collected. Following the Facts link for the name field of this entity shows that the value was initially “Article 4 Agricultural Land Restriction (1952) Area 1”, but this was superseded by a new fact on 17/07/2024 with a value of “Article 4 Agricultural Land Restriction Area 1”.
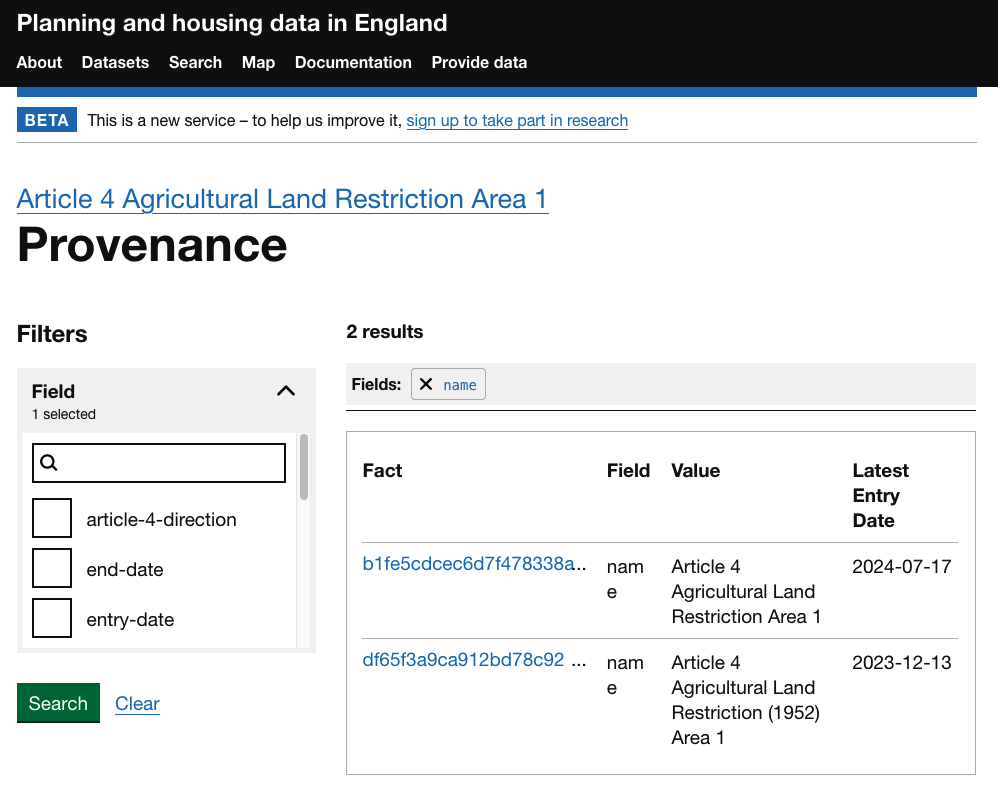
The link to this individual fact will show us the resources that this was captured from.
So there you have it! We’ve traced the journey from an endpoint through resources and facts to the entities that end up on the platform, and how this system helps us record the provenance of the data that we hold.
Credits: Swati Dash (Data Governance Manager), Steve Messer (Strategic Product Lead), Owen Eveleigh (Tech Lead), Paul Downey (Service Owner).