Weeknote—14 July 2023
Updating our collection of brownfield land data
We’ve been working on bringing our brownfield land data up-to-date. Of the 339 local planning authorities we identified that 117 new sources of data needed to be added. So far, the team have been able to add 82 of these and there are around 15 sources of data that are problematic and require us to speak with the relevant LPA to try and resolve the issues.
Health of our data
We have created a jupyter notebook which we will use as an mvp for reporting on the health of our data. Currently it focuses on analysing the health of the endpoints which data publishers have provided us.
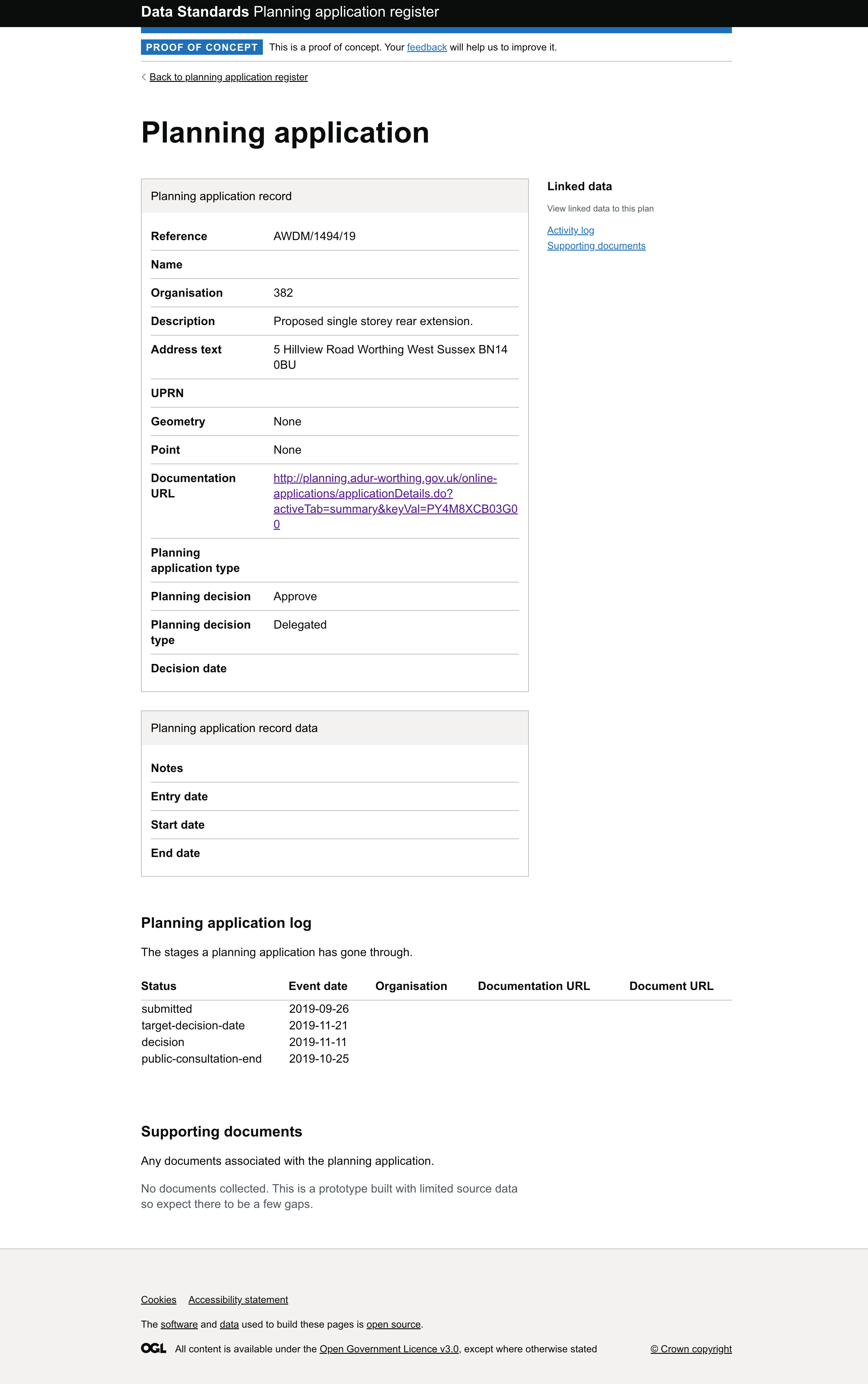
Testing the specification for planning applications
We’ve continued to test our draft planning application specification by attempting to collect data from 3 local planning authorities who are already publishing application data.
We were interested to see how closely existing data aligned with our proposed standard without the local planning authority needing to make any changes.
So far we’ve been able collect ~100,000 planning application records from Camden, Adur & Worthing, and Nottingham. The data that they were publishing was available in a mixture of .csv and GeoJson formats.
Whilst we were able to turn the three sets of data into a single coherent dataset that process was quite laborious, in particular when trying to extract data for the planning application log. We’re keen to work with each of the local authorities to explore the feasibility of them publishing data that aligns more closely to the proposed standard.
Visualising the data we’ve collected
We’ve started building prototyping to visualise the planning application data. We hope that it’ll help with two things:
-
Provide an easier way for users to explore the data that we’ve been able to collect, and to show how data modelled as per the specification can be used to help build services
-
Demonstrate where there are gaps in the existing data. These gaps may be because the information isn’t being published, or that its being published but in a way that we’re not able to reliable collect and transform it