Architecture Decision Records (ADRs)
Architecture Decision Records (ADRs) capture important architectural and technical decisions made during the design and delivery of this service. They record the context of a decision, the options considered, and the outcome, so that future teams can understand not just what was decided, but why.
Using ADRs helps us maintain a clear decision history, supports transparency, and makes it easier to revisit or challenge earlier assumptions as the service evolves. This approach aligns with good practice across government digital teams, including guidance from the Government Digital Service on documenting and communicating technical decisions, and wider GOV.UK Service Manual guidance on technology and architecture.
20. Use Customer-Managed KMS CMK for CloudWatch Logs encryption (CKV_AWS_158)
Date: 2025-12-30
Status
Approved
Context
Checkov control CKV_AWS_158 – Ensure CloudWatch Log Groups are encrypted with a customer-managed KMS key requires that AWS CloudWatch log groups use a customer-managed AWS KMS key rather than leaving log groups unencrypted or using less controlled defaults.
To meet this control and align with MHCLG security and compliance requirements, we must explicitly define how KMS keys are created, managed, and applied to CloudWatch log groups within our Infrastructure-as-Code (IaC) workflows.
Decision
We have decided to create and manage a dedicated customer-managed KMS key (CMK) using Terraform and use this CMK to encrypt all CloudWatch Logs log groups by explicitly setting kms_key_id on each log group.
Consequences
As a result of adopting a customer-managed KMS CMK for CloudWatch Logs:
- Positive Outcomes:
- Full compliance with Checkov control CKV_AWS_158.
- Centralised and consistent encryption strategy managed via Terraform.
- Negative Outcomes:
- Additional operational overhead to manage KMS keys (policies, rotation, lifecycle).
- Terraform configurations become slightly more complex due to explicit key management.
19. Use Customer-Managed KMS CMK for SSM Parameter Store encryption (CKV_AWS_337)
Date: 2025-12-19
Status
Approved
Context
Checkov control CKV_AWS_337 – Ensure SSM parameters are using KMS CMK requires that AWS Systems Manager (SSM) Parameter Store parameters are encrypted using a customer-managed AWS KMS key, rather than the default AWS-managed SSM key (aws/ssm).
By default, SSM Parameter Store encrypts SecureString parameters with an AWS-managed key, which provides encryption at rest but limits our ability to enforce fine-grained access controls, key rotation policies and alignment with internal security standards.
To meet this control and align with MHCLG security and compliance requirements, we must explicitly define how KMS keys are created, managed, and used for SSM Parameter Store encryption within our Infrastructure-as-Code (IaC) workflows.
Decision
We have decided to create and manage a dedicated customer-managed KMS key (CMK) using Terraform and use this key to encrypt all SSM SecureString parameters instead of relying on the default AWS-managed SSM key.
Consequences
As a result of adopting a customer-managed KMS CMK for SSM Parameter Store:
- Positive Outcomes:
- Full compliance with Checkov control CKV_AWS_337.
- Centralised and consistent encryption strategy managed via Terraform.
- Negative Outcomes:
- Additional operational overhead to manage KMS keys (policies, rotation, lifecycle).
- Terraform configurations become slightly more complex due to explicit key management.
18. Checkov for Infrastructure-as-Code (IaC) security scanning
Date: 2025-12-16
Status
Approved
Context
In order to enable a full infrastructure CI/CD pipeline, we require automated security scanning of Infrastructure-as-Code (IaC) to ensure that security best practices and compliance controls are enforced consistently and early in the delivery process.
The selected tool must integrate seamlessly into our CI/CD workflows, provide fast and actionable feedback to developers, and prevent insecure infrastructure configurations from being promoted to higher environments. Additionally, the solution should support our current IaC technologies while allowing for future expansion without introducing additional tooling complexity.
Two primary candidates were evaluated and both tools are well-established and widely adopted for IaC security scanning.
- Checkov (by Prisma Cloud)
- tfsec (by Aqua Security)
Decision
We have decided to adopt Checkov as the primary IaC security scanning tool instead of tfsec for the following reason.
- Broader IaC and platform support - Checkov supports multiple IaC frameworks such as Terraform, CloudFormation and dockerfiles etc.
- Unified Policy Engine - Checkov provides a centralised policy engine and built-in support for compliance frameworks such as CIS, NIST etc.
- Support native GitHub Actions CI integrations
- Support multiple output formats (CLI, JSON, SARIF)
- Checkov classifies issues by severity (LOW, MEDIUM, HIGH, CRITICAL) and also allows filtering by severity.
Consequences
As a result of adopting Checkov, it will be implemented as a new GitHub Actions workflow and executed on every pull request and on the main branch.
- Positive Outcomes:
- Infrastructure security scanning is integrated into GitHub PRs, providing early feedback on security issues before changes are merged.
- Initial soft-fail configuration ensures that the pipeline and pr merge process are not blocked while teams become familiar with the tool.
- Scan results will be generated in SARIF format and centralised review of the security findings.
- Negative Outcomes:
- Security findings will not block merges during the initial rollout, which may allow known issues to reach the main branch.
- Developers may need time to interpret and act on new security findings introduced by the scans.
17. Automate EBS volume snapshots with aws Data Lifecycle Manager (DLM)
Date: 2025-08-22
Status
Approved
Context
We need an automated and consistent backup solution for aws EBS volumes with minimal operational overhead. Manual or script-based approaches are error-prone and make compliance/auditing difficult. We already manage aws resources via Terraform and prefer a native, low-maintenance option.
To control the aws snapshot storage costs, we will restrict automated snapshots to the production environment only. Development and staging will continue without automated EBS backups.
Additionally, aws Trusted Advisor includes a best-practice check for EBS Snapshots. It recommends that all critical volumes have recent snapshots to protect against data loss. Our current setup does not consistently meet this recommendation.
Decision
Adopt aws Data Lifecycle Manager (DLM) to create daily EBS snapshots for production volumes, with short retention policy to control costs and managed via Terraform.
- DLM lifecycle policy targeting resource_types = [“VOLUME”]
- Daily schedule at 07:00 UTC
- Retention: 2 DAYS
- Feature flag with var.enable_ebs_snapshot which only enabled in production.
Consequences
- Compliance: Satisfies aws Trusted Advisor’s “Amazon EBS Snapshots” check, ensuring production EBS volumes have recent backups and strengthening audit posture.
- Reliability & simplicity: Managed service handles scheduling, retries, and orchestration, no custom code or cron/Lambda to maintain.
- Production safety: Ensures critical workloads have daily recoverable EBS snapshots with automated retention policy.
- Cost control: By limiting to production only, snapshot storage costs are minimised. Non-prod (dev/staging) avoids unnecessary backup overhead.
16. Introduce entity_subdivided Table to Store Subdivided Geometries of Complex datasets
Date: 2025-04-30
Status
Approved
Context
Spatial queries on datasets containing large and complex geometries (e.g., flood-risk-zone) were observed to be slow and resource-intensive. To address this, an initial optimisation was implemented by creating a new table, entity_subdivided, to store subdivided versions of complex dataset geometries. This significantly improved query perfomance.
Decision
- A new table called entity_subdivided introduced to store subdivided geometries for complex datasets
- Subdivided geometries will be stored alongside their entity and dataset identifiers
- The querying logic will check for the presence of a subdivided geometry in entity_subdivided and use it if available.
- If not available, the original geometry from the entity table will be used as a fallback.
Consequences
- Improved performance of spatial queries involving complex geometries across datasets.
- Additional storage is required to hold subdivided geometries.
- Query logic complexity increases slightly to support dual-source geometry selection (entity vs entity_subdivided).
15. ADR - Coderabbit.ai Pilot for Public Repositories Only
Date: 2024/10/17
Status
Pending
Context
We are planning to pilot the use of Coderabbit.ai, an AI-powered tool designed to enhance code review and development efficiency. The goal is to evaluate its potential benefits in improving code quality, identifying bugs, and speeding up the development process. To manage the scope, we will initially limit this pilot to the Submit repository, which is integral to our system but has manageable complexity. Expanding the pilot to other repositories will depend on the success of this trial.
Decision
We will implement a pilot program for Coderabbit.ai focusing exclusively on the Submit repository. The pilot will aim to:
- Measure the tool’s impact on code review times and quality (eg. Number of errors in sentry).
- Evaluate how well Coderabbit integrates with our existing processes (eg. Code Review / Quality Checks).
- Assess user satisfaction and ease of use among the development team.
- Document any challenges or limitations encountered.
- This must only be applied to public repos, no private repos should be considered at this time.
The decision to expand the use of Coderabbit.ai to other repositories will be made based on the pilot’s success metrics, which include improvement in code quality, efficiency gains, and feedback from users.
Consequences
-
Positive Outcomes:
- If successful, we will expand the pilot to other repositories, potentially increasing development efficiency across the board.
- Enhanced code review quality and faster identification of bugs or issues within the Submit repository.
- Valuable insights gained from using AI in the code review process that can influence future decisions on tool adoption.
-
Negative Outcomes:
- If the tool does not meet expectations, the time and resources spent on the pilot may not yield the desired results, leading to a reassessment or termination of the initiative.
-
Operational Impact:
- Code Review on the Submit repo might slow temporarily as teams adjust to using the tool and provide feedback for improvements.
14. Use NodeJS to serve the frontend of the new data validation tool and interact with other APIs
Date: 2023-10-24
Status
Pending
Context
We need some way to serve our frontend to users, and handle forwarding requests onto our other APIs needed for validation. at the moment the requirements on this are fairly limited, but we want the room to grow if needed.
Decision
We will start with a simple nodeJS application and will review if this was the right call a couple of weeks from now.
All the buisness logic should be delegated to other APIs, and exception to this will be documented.
Consequences
- This approach would have slight performance improvements over fastAPI.
- Prototypes produced by our designer Adam Silver can be easily used as a starting point as they are built with nunjucks and the gds.
- Frontend developers may find it easier to onboard as they will be familiar with the tech stack. and wont need to upskill in python.
- We should be careful not to include too much business logic within the nodeJS application, or risk needing our developers to upskill in nodejs and fastapi.
- We will be able to use the official GDS frontend toolkit, which will make it easier to build a consistent UI. as opposed to using the unofficial python port / nunjucks implementation of the GDS frontend toolkit.
13. Use PyTest and JSONSchema as the Contract validation and testing solution
Date: 2023-10-24
Status
Pending
Context
Ideally, we would like to:
- test messages flowing in and out of our API endpoints - Requests & Responses
- establish message schemas for the service-oriented elements of the Products we create
Decision
We will develop a suite of tests (over time) that will typically
be run by the CI/CD pipeline.
The tests will be based on the PyTest framework as it has proven to
be an effective testing framework, and is already used extensively in our code base.
The tests will focus on:
- validating that correct messages produce valid,
and expected responses. - validating that incorrect messages produce a suitable error response
Consequences
- The approach assumes that the API front end is capable of injecting the validation service as a dependency.
- The approach may prove too simplistic and need replacing with something better suited to the purpose.
- The first tests will be based on the FastAPI framework. If we later decide to use another framework,
the tests will extensive re-factoring to continue working
12. Use vector tiles to display geographic data on a map
Date: 2021-07-22
Status
Accepted
Context
We need to be able to display multiple geography datasets on a map. These vary from large to small datasets, with
varying densities and scales. The geometry data is converted to GeoJSON and stored in the view model. Points for
consideration
- the map should be performant
- it should be quick to add/modify a dataset
- it should be possible to style each dataset individually
- the data should be provided in a widely supported format
- retrieval of data should be fast, efficient and scalable
Decision
Geographic data should be served as vector tiles using Datasette and the MBTiles specification. This involves a
conversion step from GeoJSON to vector tiles, where some processing is done to package data into tiles corresponding to
different grid cells and zoom levels. Each dataset will produce its own corresponding tileset. The vector tile server is
hosted via Datasette on a dedicated instance. Access to this data is provided through Datasette’s API and through a
source url that is compatible with vector-based map libraries.
Consequences
- This approach allows the map to be performant as it will only request the tiles necessary for the viewport. This also
reduces the load on the tile server. - Vector tiles are optimised for different scales
- Vector tiles allow for styling individual layers (datasets)
- Since each dataset has its own tileset, a dataset toggle feature on the map will only retrieve the dataset(s)
requested by the user - It is possible for users to download the vector tilesets for their own use. It is packaged in MBTiles (sqlite), a
well-known format. - The tile server simply serves the tile requested - there is no expensive logic or spatial queries required.
- The generation of the tilesets is an added time cost to our CI/CD pipeline.
- We should be careful not to use conversion options that change the underlying data (e.g. removing polygons/points)
11. Missing entry-dates
Date: 2021-04-20
Status
Proposed
Context
The entry-date field is a very important part of all of our data schemas. It is this entry-date that allows us to
sequence entries and ultimately provide an accurate snapshot of the data as it is or was at a given point in time. Due
to the criticality of the entry-date, when this value is missing from an entry it presents us with a problem. The
pipeline contains some logic that will set missing entry-dates to a default value (currently the date on when we first
collected the resource containing the entry), but this is not reliable.
This problem becomes particularly acute when dealing with historic resources that are missing entry-dates. If we start
collecting a historic resource on 1st Jan 2021, that date will be used as the default for any missing entry-dates
despite the fact that this data may have been published decades earlier. Suddenly these historic entries would take
precedence over any other data collected prior to 1st Jan 2021.
Decision
It’s impossible for us to guess the correct value for the entry-date, so we will instead accept that these dates are
imperfect. In the case where we know for certain that an entry-date is incorrect and this is causing data accuracy
issues (e.g. as described above), we will use the existing patching mechanism to correct it.
Consequences
- We should be explicit with data providers about the importance and usage of the entry-date field, so that they can
treat it with the care it deserves (where possible). - The existing mechanism to default missing entry-date values to the date of the first collection will remain in place.
- Patches should be added to set entry-date in cases where it is known to be wrong.
- Data providers will have visibility of any changes that our processes make to entry-date values, so that they can
correct the source data ahead of any future submissions (where possible).
10. Write new tests at the lowest possible levels
Date: 2021-03-09
Status
Proposed
Context
Software testing can occur at different levels and different granularities. A well-developed CI pipeline will require a
test suite that finds the balance between speed and coverage. Low level tests, such as unit tests, are fast to run and
target a specific ‘unit’ of code. High level tests, such as end-to-end tests, focus on behaviour and application
workflow. These tests have wider coverage but take longer to execute.
Decision
We should aim to test a feature or development extensively at the lowest possible levels. This will allow the test suite
to remain fast. It will also increase the chance of catching issues earlier and making them easier to debug. This should
not preclude us from adding high level tests where appropriate; often these will only need to cover a happy path
scenario.
See here for more details.
Consequences
9. Use the Entity-Value-Attribute pattern for our data model
Date: 2021-03-08
Status
Proposed
Context
We need a data model to represent the data we collect.
The model is likely to change frequently as we add new types of entity, each with potentially new attributes.
The model also needs to be be able to store the history of changes to an entity.
The same information may be found in multiple resources, we need to be able to cite the resources where each fact came
from, its provenance.
Decision
Load transformed resources into a Entity-attribute-model.
The model should provide a “fact” identifier for each entity-attribute-value triple.
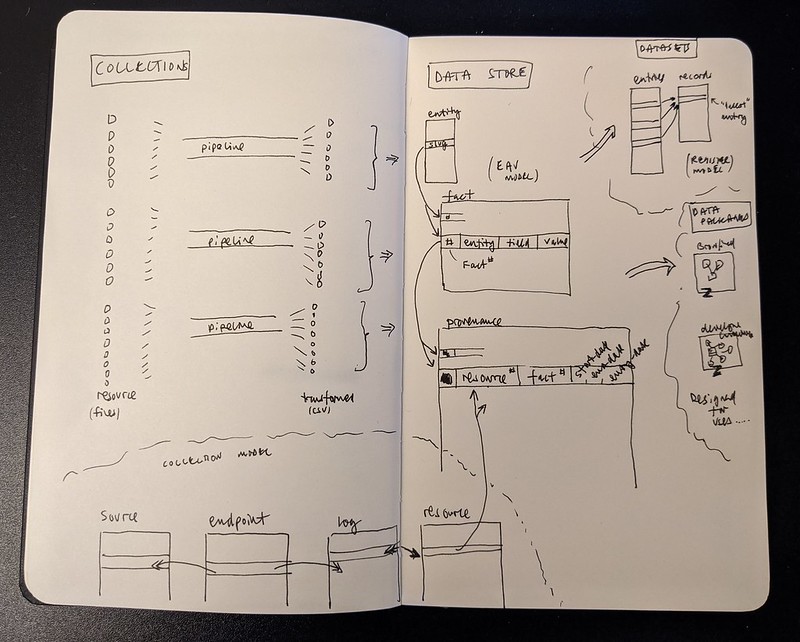
Consequences
- The model may then be used to link a fact to the list of resources which provide the fact, and from the resources we
can show its provenance, when and from where the resource was collected. - Querying an EAV model is more complicated and expensive. We may need other models to render pages, these can be data
pacakges: see 9. Use SQLite for data packages. - The specification can still be used to document, check, and control how we process data in this schema-less model.
8. Avoid git submodules wherever possible
Date: 2021-03-08
Status
Proposed
Context
Git submodules allow you to keep a Git repository as a subdirectory of another Git repository.
Git submodules are simply a reference to another repository at a particular snapshot in time.
Git submodules enable a Git repository to incorporate and track version history of external code.
(taken from https://www.atlassian.com/git/tutorials/git-submodule)
Unfortunately, git submodules are a very rudimentary way to share code between projects and is
very clumsy and cumbersome to work with in practice. In reality, code sharing should be via
distributable packages rather than sharing whole source code repositories.
Decision
Instead of git submodules, make use of appropriate dependency management (i.e. Pip for Python, Bundler for Ruby,
NPM for Javascript) in order to use external code in a controlled, versioned manner.
Consequences
- New projects should not use git submodules
- Existing or adopted projects using git submodules should be migrated where possible
7. Use Github LFS for large git files
Date: 2021-03-08
Status
Proposed
Context
Some datasets involve the collection of large resources. These files cannot be easily stored in version control.
However, they should be associated with the repository and it should be possible to retrieve them easily if necessary.
There are several options for hosting these files.
Decision
Hosting these files on Github is the most straightforward option as it doesn’t require third-party/custom tooling (Git
LFS requires a hosted server).
Consequences
There is a cost associated with hosting on Github. Users will need to have Git LFS installed in order to be able to
retrieve large files.
6. Use kebab-case for names in data
Date: 2021-03-08
Status
Proposed
Context
Kebab case – or kebab-case – is a programming variable naming convention where a developer replaces the spaces
between words with a dash.
Decision
TODO
Consequences
TODO
5. Load external frontend assets first
Date: 2021-03-07
Status
Accepted
Context
The order the frontend assets are loaded matters.
We use a number of 3rd party assets, as well as writing our own CSS and JS. For example, our CSS builds on the GOV.UK
frontend CSS. Likewise, our JS builds on the GOV.UK frontend JS. Therefore we need to include the 3rd party assets
before our assets.
Decision
3rd party assets are loaded before Digital land frontend assets.
Add CSS link elements to the head, before dl-frontend.css. E.g.
{% block dlCss %}
<!-- link tags for 3rd party stylesheets go here -->
{{ super() }} # this includes all the digital land defined stylesheets
{% endblock %}
Add Javascript to the end of the body, before dl-frontend.js. E.g.
\{\%- block bodyEndScripts \%\}
\{\{ super() \}\} # this includes all the digital land defined JS
\{\% endblock \%\}
There will be times when you choose to load JS in the head to help maintain the dependencies. For example, it makes
sense to keep the CSS and JS required for leaflet maps together.
We load these in the head.
Consequences
- 3rd party assets won’t override our assets
- Our CSS and JS can build on code inherited from 3rd party assets
- Debugging is easier because we can trace the order CSS and JS is loaded
- Using jinja blocks means we can maintain fine grain control on a specific page if we need to
- Loading stylesheets in the head means the user should see the page content as you intended
- Loading JS at the end of the page means failing JS will not block the page from loading. Important for our progressive
enhancement approach to JS
4. floating-package-dependencies
Date: 2021-03-05
Status
Accepted
Context
We’ve experienced conflicting package versions when between those installed by the digital-land-python repository, and
those pinned in a requirements.txt
file.
Decision
List the smallest possible number of packages as dependencies, and don’t pin the version of packages, as in this example
requirements.txt file:
-e git+https://github.com/digital-land/digital-land-python.git#egg=digital-land
We may move back to frozen, pinned packages in a setup.py once our core python code is more stable, or is packaged and
installed via PyPi.
Consequences
- Moving to unpinned versions reduces the risk of conflicting versions with those listed in other packages.
- Reducing the number of dependencies makes it easier to undersand the packages directly required by a repository.
- It’s possible to break repository if it depends on a package installed as a dependency to another package, and that
implicit dependency is removed.
3. Use the repository-pattern to access a database
Date: 2021-03-05
Status
Proposed
Context
As we introduce a database into our architecture it will be useful to agree some access patterns so that we have a
shared understanding of what “good” looks like when writing code and performing code reviews. The key considerations for
choosing an approach include:
- testability; it should be easy to write unit tests without the need to connect to a real database
- readability; it should be easy to write code that makes the database interactions easy to understand
- encapsulation; all of the specific code/queries required to implement the underlying persistence technologies, should
be contained in their own module(s)
The commonly used Repository Pattern provides access to the underlying persistence via an abstraction that is written
in the language of the domain. It gives the developer a clear interface that can be used to create a test double (likely
storing data in-memory) and encapsulates all queries relating to a single “aggregate” in one place.
NB An aggregate is a cluster of associated objects that we treat as a unit for the purpose of data changes
Example
Because Provenance requires a Fact in order to be meaningful, Fact and Provenance may be grouped together into a Fact
aggregate, served from a single FactRepository. Another way to think about this is to consider how the data will be
accessed. It is unlikely we would have a page per Provenance entry; it’s just too fine grained to be useful. More
likely is that at the lowest level there is a page per Fact, with the relevant Provenance listed as a form of
“history”. We would also not expect external systems to reference individual entries of Provenance, but they may
reference a specific Fact.
With that in mind, here is what an interface to FactRepository might look like:
class FactRepository:
def add_entry_facts(self, entry)
"add all facts from the provided entry to the repository"
def find_by_resource(self, resource_hash)
"return all facts that were contained in the specified resource"
def find_by_entity(self, entity_ref)
"return all facts relating to the specified entity"
Decision
Use the repository pattern
Consequences
- This facilitates unit testing where the repository can be replaced with an in memory store and easily populated with
test data. - It provides a readable interface to the underlying collections
- Once in place, it is important that the repository is the only channel through which data is written or updated for a
given aggregate - It enables easier transition to different storage technologies
2. Implement plugins using pluggy
Date: 2021-03-05
Status
Accepted
Context
The pipeline has the ability to name a plugin used to
configure different behaviour and extend the core pipeline code.
For example:
- a plugin value of
wfsin the
collection/endpoint.csv
file indicates the endpoint-url is an
OGC Web Feature Service endpoint, and the GML content, which is
different each time we collect it, needs canonicalisation. Similar plugins are needed for APIs which are paginated,
or require a SPARQL or other script. - a plugin value of
fixedin the
pipeline/convert.csv
file indicates a fixed resouce file should be used instead of attempting to convert the collected resource file. - the brownfield-land pipeline
has plugin code to
harmonise an OrganisationURI value into the
CURIE needed by the organisation field.
Decision
We use the Python pluggy framework these can either be run instead of or as well as the vanilla pipeline
functions. Rather than confuse the general purpose pipeline code with conditional branches to handle one specific case.
We can inject our own version of certain functions at run time.
The Python code currently may be migrated to a package in the future, so it can be shared across pipelines.
Consequences
- We have a consitent framework for using code from third-parties.
- Our core code doesn’t have to depend on dependencies only used in a small number of pipelines.
- Plugins need to be written in Python, or have a Python wrapper.
- Developers will need documentation to understand how the pluggy framework works.
1. Record architecture decisions
Date: 2021-03-05
Status
Accepted
Context
We need to record the architectural decisions made on this project.
Decision
We will use Architecture Decision Records, as
described by Michael Nygard, starting by
recording some of our existing technical decisions, which we’ll review as a team.
We’ve elected to keep the source markdown files in the content directory to be consistent with our other render
repositories.
We can later tag decisions, and render them as HTML in the doc directory so they can be more easily searched and
navigated on the digital land site.
Consequences
See Michael Nygard’s article, linked above. For a lightweight ADR toolset, see Nat Pryce’s
adr-tools.