Batch Processing & Our Pipelines
These are the pipelines which load data into the platform.
The main implementation of our data architecture is via a set of pipelines which are scheduled (or manually triggered) via airflow. We schedule them once a night.
Airflow utilises DAGs to trigger a set of jobs/tasks. We have DAGs representing these piplines and DAGs which trigger other DAGs to run multiple pipelines int he correct order. The master DAG looks something like:
Data Collection Pipelines
We support a huge amount of piplines as each dataset needs special treatment. Each dataset belongs to a collection which has it’s own pipeline.
These pipelines do not have their own unique code, instead they use both the specification and configuration inputs to produce different behaviours.
The flow diagram is as follows:
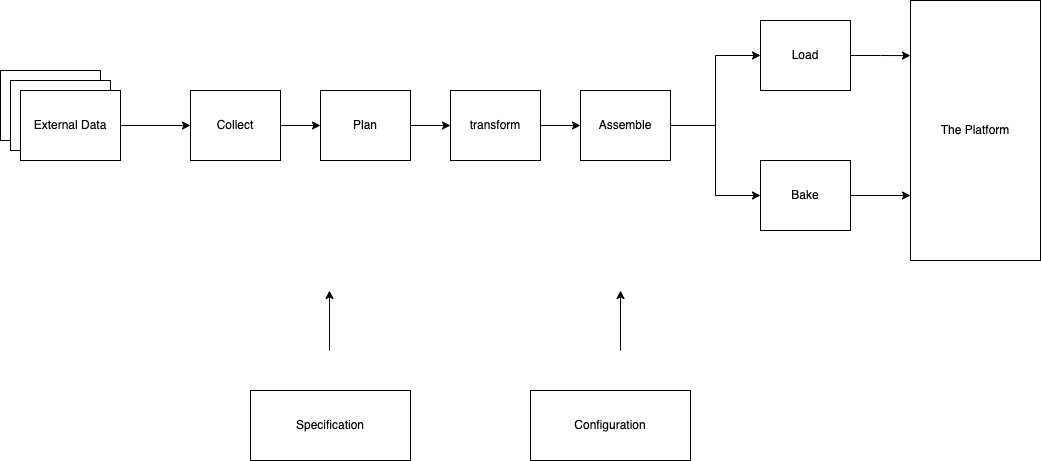
There are several key processes ran here:
- Collect - for all endpoints in this collection download a resouce and log the dowload
- Plan - given the current and historic resources create a plan of which resources to process and assemble to which dataset with appropriate configurations
- Transform - transform each resource
- Assemble - load and aggregate all files into a sqlite3 file
- Load - load the sqlite file into the platform
- Bake - create baked versions of datasets in different formats
Collect, Plan, Transform, Assemble and Package Are all schuled and triggeed using airflow. The code for the airflow DAG can be found here. the DAG is autogenerated for all datasets with a colection in our specification.
within the airflow DAG for each collection there is a collection task which is ran using ECS Fargate. The code for the container can be found here. within this one task all processes except load are ran.
The load process is automatically triggered by AWS Eventbridge when a sqlite3 file is uploaded. There are three different forms of loading that we do:
- load data into our postgis using digital-land-postgres
- load sqlite files into an EFS volumne for datasette using digital-land-efs-sync
- transform sqlite into an mbtiles file for datasette-tiles using tiles-builder
For all the repos above there is likely a reliance on digital-land-python
Data Package Pipelines
This hasn’t been generalised yet so may need some thought on generalisation moving forward. This pipeline is very simple as it just builds the organisation.csv.
It is another DAG in airflow and is triggered once the required data collection pipelines have been ran.
The build is ran using data-package-builder-task
Digital Land Pipeline
A very specific pipline which builds the digital-land.sqlite3 and performance.sqlite3 and loads the relevant information from digital-land.sqlite3 into the platform
This isn’t triggered in airflow instead it is ran as a Github action using the digital-land-builder.
Once the sqlite file is uploaded to s3 we use the same code as in the data collection pipelines to load data into our postgis using digital-land-postgres