Data quality framework
We have a structured approach to how we identify and fix issues with data quality, which we refer to as our data quality framework.
A key part of this framework is a list of data quality requirements built and maintained by the data management team.
These documented data quality requirements help the data management team understand what needs to be assessed, why it needs to be assessed, and plan how it can be assessed. We use the process below to go from identifying a data quality need through to being able to actively monitor whether or not it is being met, and then raise the issues to the party responsible for fixing them.
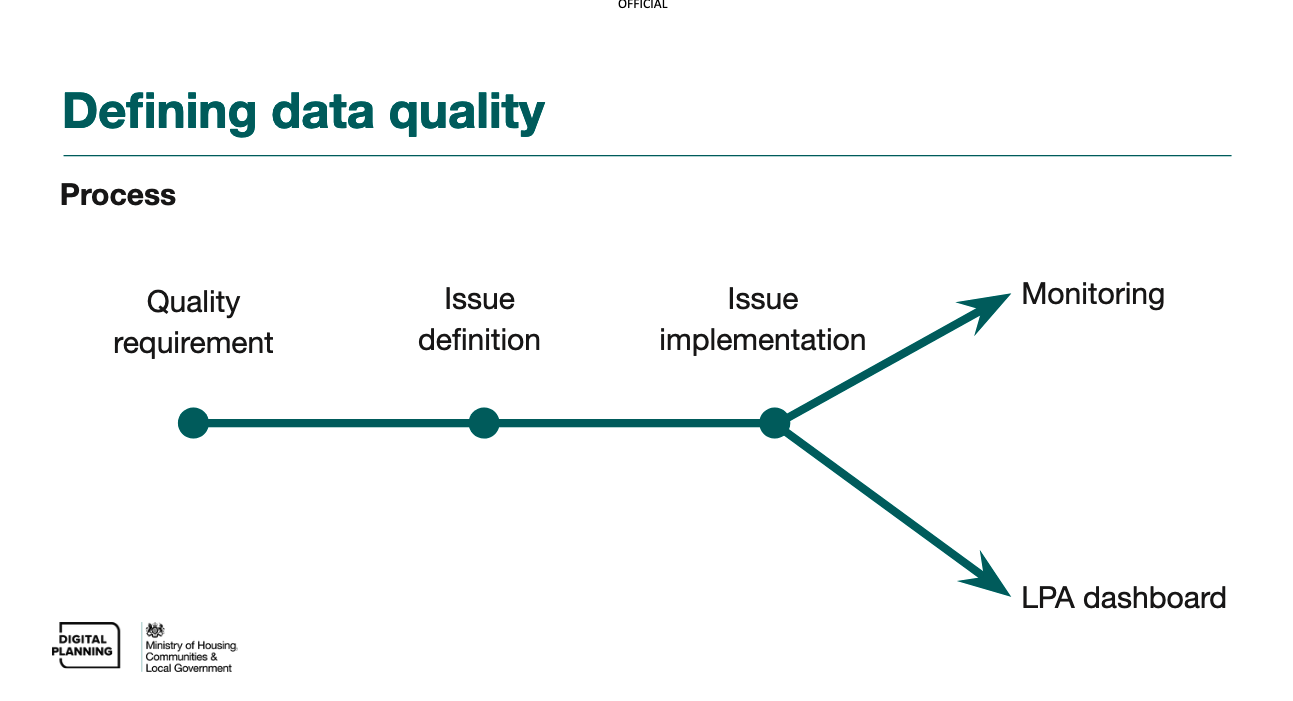
-
Quality requirement: documenting a need we have of planning data based on its intended uses.
-
Issue definition: agreeing the method for systematically identifying data which is not meeting a quality requirement.
-
Issue check implementation: automating identification of issues, either through a query or report, or through changes to the pipeline code.
-
Issue check use (monitoring): surfacing information about data quality issues in a structured way so that action can be taken.
Example
Here’s an example using a requirement we have based on the expectation that providers of our ODP datasets should only be providing data within their local planning authority boundary. This helps us identify a quality issue like if Bristol City Council were to supply conservation-area data where a polygon was in Newcastle.
Quality requirement: geometry data should be within the expected boundary of the provider’s administrative area
Issue definition: An ‘out of expected LPA bounds’ issue for ODP datasets is when the supplied geometry does not intersect at all with the provider’s Local Planning Authority boundary
Issue check implementation: expectation rules which test for any of these issues on all ODP datasets.
Issue check use (monitoring): surfacing information about out of bounds issues in the Submit service so that LPAs can act on this and fix the issues.
Monitoring data quality
Once data quality issues are defined, and checks for them have been implemented, we’re able to systematically monitor for any occurances of data quality issues.
Monitoring is carried out in one of two ways, depending on whether the responsibility for fixing the issue is external (i.e. with the data provider) or internal (i.e. with the data management team):
-
By the Submit service, to allow LPAs to self-monitor and fix issues at source
-
By the Data Management team, to resolve data quality issues that can be fixed by a change in configuration
See our monitoring data quality page which gives guidance on the processes we follow to fix quality issues raised by our operational monitoring. These processes go hand-in-hand with our data quality requirements, which defines our full backlog of requirements, issue definitions and monitoring approach.
Note: The Data Management team also has a defined process for tackling ad-hoc data quality issues which are raised for data on the platform. This begins with an investigation, followed by one or both of a data fix and root cause resolution. This process may also result in the formal definition of a data quality requirement and issue check so that it can be handled in future through the data quality management framework.
Measuring data quality
With well defined data quality requirements and issues, it’s possible to use them to make useful summaries of data quality at different scales, for example assessing whether the data on a particular endpoint meets all of the requirements for a particular purpose.
We’ve created a data quality measurement framework to define different data quality levels based on the requirements of ODP software. This measurement framework is used to score data provisions (a dataset from a provider) and create summaries of the number of provisions at each quality level.
The table below visualises the framework:
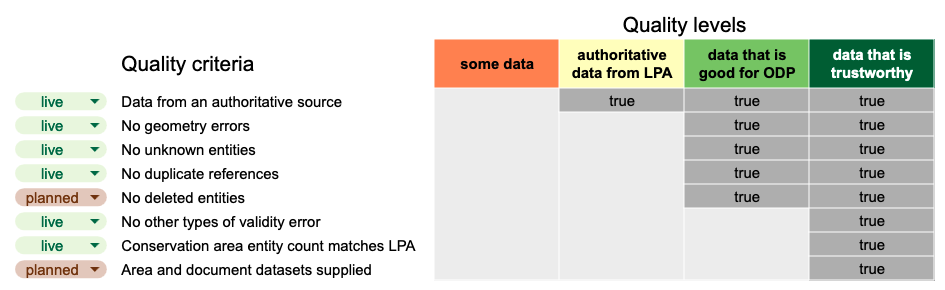
The criteria marked as “true” at each level must be met by a data provision in order for it to be scored at that level. Therefore the framework defines 5 criteria that must be met in order for a data provision to be good for ODP. The levels are cumulative, so those same 5 criteria plus 3 more must be met in order for a provision to be scored as data that is trustworthy. Where we have data from alternative providers (e.g. Historic England conservation-area data) the first criteria cannot be met so it is scored as the first quality level, some data.
Each of the criteria are based around one or more data quality requirements. For example, the “No other types of validity errors” criteria is based on meeting 7 different data validity requirements from the specifications, while the “No unknown entities” criteria is based on just one timeliness requirement. We track how requirements are mapped to criteria on the measurement tab of the data quality requirements tracker.
The framework is flexible and allows us to add more criteria to each level, or re-order them as required. Note that the criteria marked as “planned” are in development, and will be able to be used in the measurement framework once live.
The chart below is an example of using the framework to measure the quality levels across all ODP dataset provisions (on 2024-11-20):
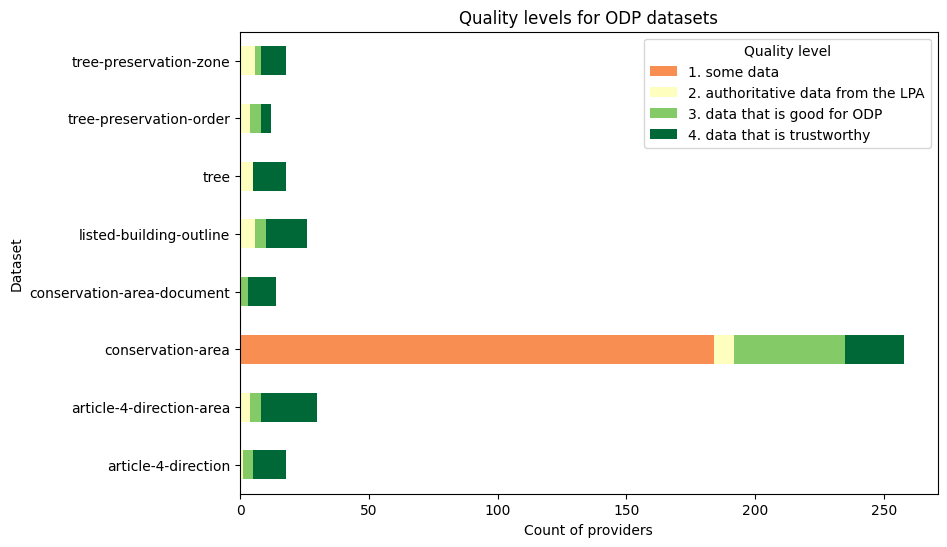
(see quality reporting in the jupyter-analysis repo for up to date versions)