Collect
the collect process is used in our data collection pipelines to download a resource from an endpoint. It produces a collection log per endpoint for that given date.
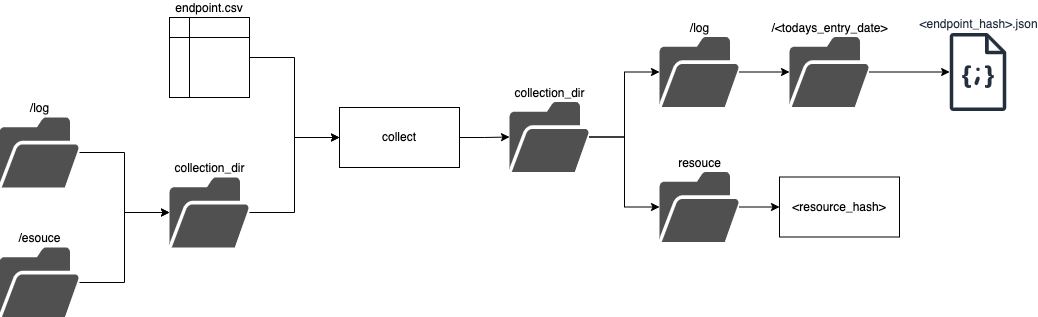
The collect process takes a csv which should correspond to the Endpoint dataset specification and a single directory in which two outputs are reorded:
- log - a log json file is created the file is named after the hash of the endpoint which was checked. it is added into a
logdirectoy. This diectory is patitioned byentry-date. - resource - a file (could be any format) nammed afte the hash of the contents of a file. this data file will always be refeed to as this in our system
digital-land-python
the collect process uses a small amount of code from digital land python. The command found in the commands.py file. The command offers a functional way of collecting resources but the heavy lifting is done by the Collector class found in in collect.py.
Batch Implementation
This process is run as part of our data collection pipelines.
they are ran during a task in our collection dags in airflow. The file generating these dags can be found here.
The airflow triggers an ECS task in fargate and uses the collection-task repository
the script for all procesess ran in the ECS Task is run.sh
In that script the make collect target is used which leads
to the digital-land cli:
digital-land ${DIGITAL_LAND_OPTS} collect <ENDPOINT_CSV> --collection-dir <COLLECTION_DIR>)
The arguement options are passed in by setting environment variables. defaults are chosen via make if not set.
Once complete results are pushed to s3 and saved using another make target
dynamic implementation
ran as part of the following tasks:
- check_url