Plan
The plan process does a combination of things specifically:
- update the resource and log csvs after new logs have been created in the collect pocess
- create a makefile which can be ran trigger following processes (for transform even in paralell)
This takes in very similar information as the collect process but is mainly there to make a plan for future processes based on the collection logs and other files
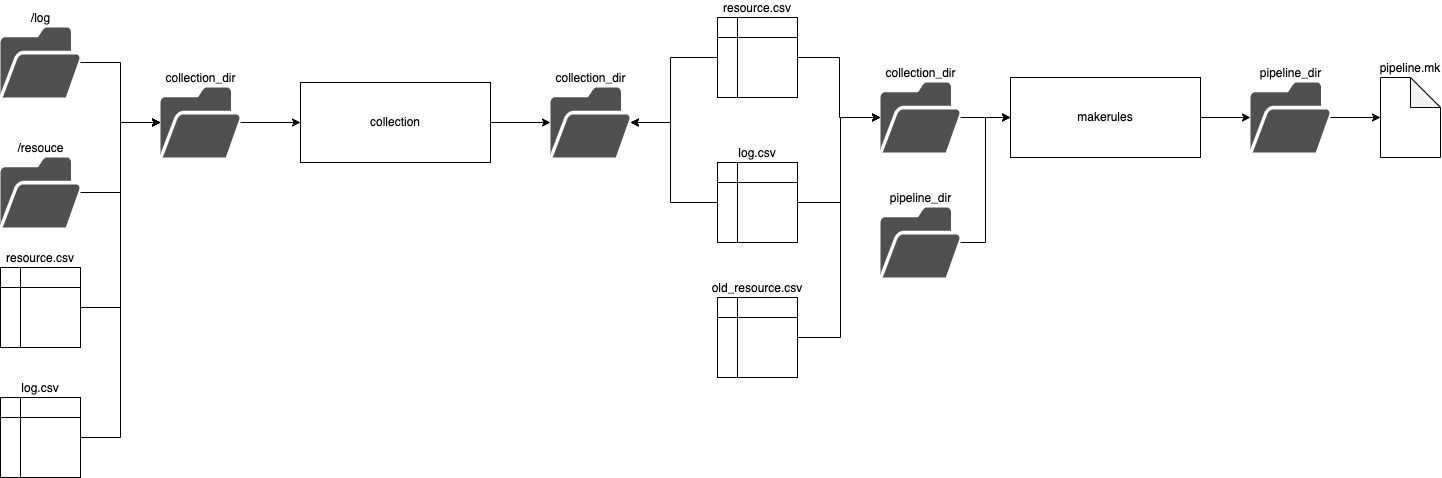
The plan process takes the collection directory where it assumes the associated files are kept:
- log directory - a log json file is created the file is named after the hash of the endpoint which was checked. it is added into a
logdirectoy. This diectory is patitioned byentry-date. this is produced by the collect phase - resource directory - a file (could be any format) nammed after the hash of the contents of a file. this data file will always be refeed to as this in our system
- log.csv - a csv that contains relevant information from all the json logs. if no csv is present it assumes there is no historic logs
- resource.csv - a csv created from logs that lists all resources collected and associated information
- endpoint.csv - contains the endpoint information
- source.csv - contains the souce information
The outputs from the first step are as follows:
- log.csv - an updated version of the log.csv with the additionnal logs from any recent collect process added
- resource.csv - an updated resouce.csv which contains any new rersources gathered in more recent logs as well as updating old resources with any changed information in the source or endpoint csvs
the outputs from the second step
- pipeline.mk - a file that can be used by make to process all resources and create dataset sqlite files
digital-land-python
the plan process uses a small amount of code from digital land python repo. The two commands are found in the commands.py file. collection_save_csv and collection_pipeline_makerules
The commands offer functional ways of building the required files but the heavy lifting is done by the Collection class found in in collection.py.
Batch Implementation
This process is run as part of our data collection pipelines.
they are ran during a task in our collection dags in airflow. The file generating these dags can be found here.
The airflow triggers an ECS task in fargate and uses the collection-task repository
the script for all procesess ran in the ECS Task is run.sh
In that script the make collection target is used which leads
to the digital-land clis:
digital-land ${DIGITAL_LAND_OPTS} collection-save-csv --collection-dir $(COLLECTION_DIR) --refill-todays-logs $(REFILL_TODAYS_LOGS)
digital-land ${DIGITAL_LAND_OPTS} collection-pipeline-makerules --collection-dir $(COLLECTION_DIR) --specification-dir $(SPECIFICATION_DIR) --pipeline-dir $(PIPELINE_DIR) --resource-dir $(COLLECTION_DIR)resource/ --incremental-loading-override $(INCREMENTAL_LOADING_OVERRIDE) > $(COLLECTION_DIR)pipeline.mk;
The arguement options are passed in by setting environment variables. defaults are chosen via make if not set.
Once complete results are pushed to s3 and saved using another make target