Open Design Proposal 001 - Publish service - Async
Author(s) - Chris Cundill
Status
Closed
Introduction
The first iteration of the Check service (originally named Publish service) offers validation of data files via an
upload. Interaction with the user is currently synchronous, meaning that a user uploads their data file and waits for
an immediate validation response. The service needs to scale to support many more data sets and concurrent users meaning
that the this approach is likely to result in system failure and/or poor user experience.
Causes of system failure might include:
- Gateway/request timeout: requests take too long to process due to the size
- Out of memory: available memory might be ‘maxxed’ out when trying to handle multiple large data files concurrently
- No more disk space: disk space might also be exceeded when trying to handle multiple large data files concurrently
- Request size too large: uploads of large files might exceed what the gateway or web servers are able to handle
Meanwhile, poor user experience might be caused by excessive wait times for validation of large files.
During development of the current service, it was observed that a data file of ~11MB was taking over 30 seconds to
process. Clearly, there are genuine scenarios where it will not be feasible to provide validation responses to end
users synchronously.
Detail
Overview
In order to address the problems outlined, the following changes are proposed:
- Respond to validation requests asynchronously
- Upload files direct to S3
By responding to validation requests asynchronously, the system is able to fulfil a user’s request in a manner that
minimises the risk of system failure. Memory and disk space can be optimised for processing each individual request.
A database will be introduced to persist requests and validation results while a queue will be used to trigger
asynchronous processing of requests.
By uploading files directly to S3, large files will be handled by AWS’ dedicated infrastructure designed for multipart
uploads. Gateways, web servers and APIs do not need to be scaled for file-based requests. In addition, allocated disk
space does not need to cater for storage of multiple concurrent uploaded files.
Containers
Structure
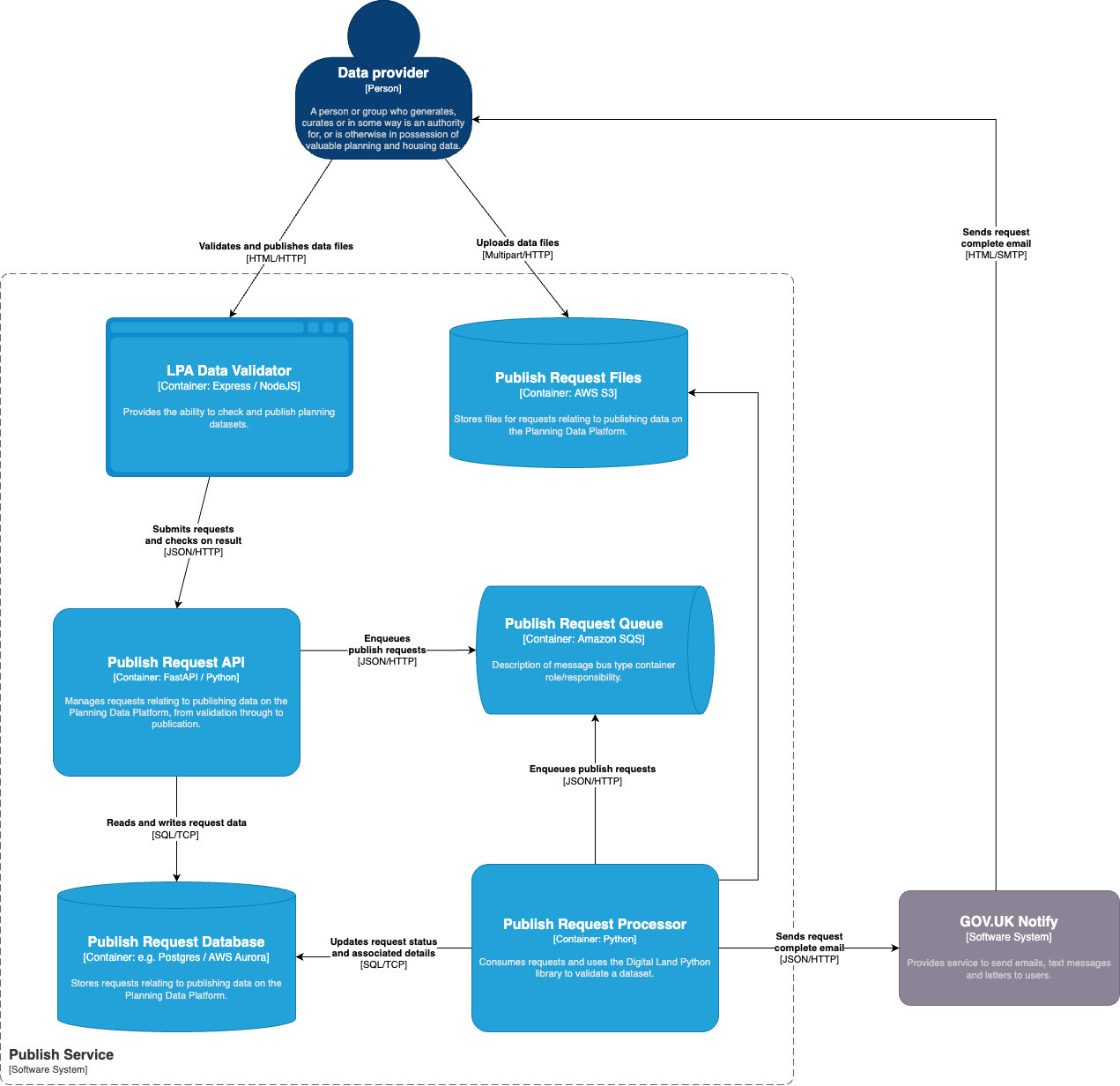
The Publish Request API will manage request data and persist such to a Postgres database.
An SQS queue will be used to trigger request to be fulfilled by the Publish Request Processor.
The Publish Request Processor will process just one request at a time meaning its CPU, memory and disk requirements
need only be as large as is necessary to process one file. Running multiple instances of the Processor allows the
system to process multiple requests concurrently.
GOV.UK Notify will be used to send an email notification to users
Interaction
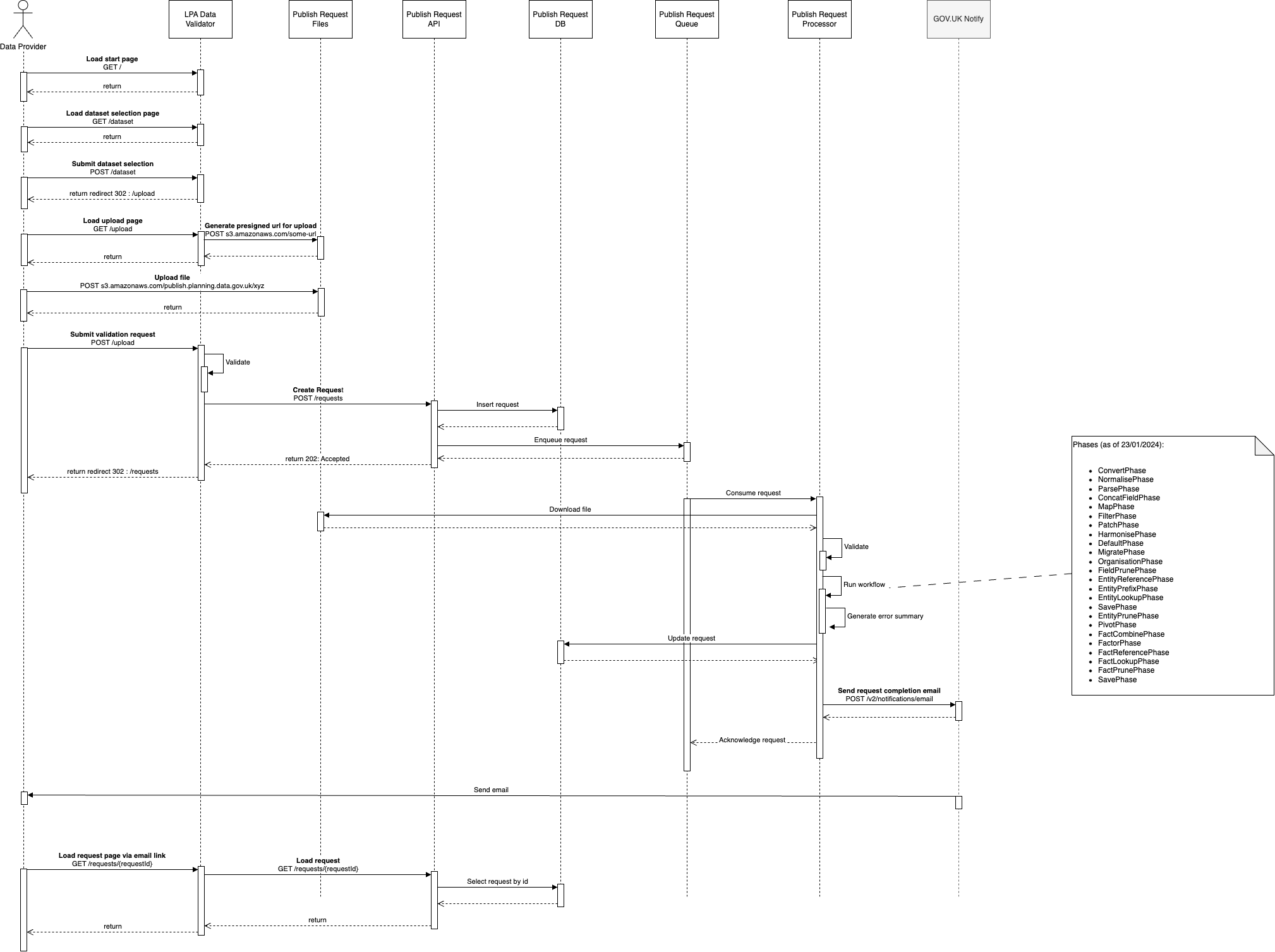
Testing
In order to validate the solution and indeed arrive at the correct assignment of compute resources (e.g. CPU, memory and disk),
it will be necessary to undertake load testing. This testing will also help determine the necessary number of processors
required to meet concurrency targets.
One possible method for the load testing could be using AWS’s Distributed Load Testing pattern
(see https://aws.amazon.com/solutions/implementations/distributed-load-testing-on-aws/).
Implementation considerations
-
New AWS resources will need to be provisioned for:
- Publish Request Database (Postgres on AWS RDS Aurora)
- Create empty database and app users for Publish Request API
- Publish Request Queue (SQS)
- Publish Request Files (S3 Bucket)
- Publish Request Database (Postgres on AWS RDS Aurora)
-
New code repositories, GitHub pipelines, ECR image repositories and ECS tasks will be needed for:
- Publish Request API
- Service should be able to migrate/mange own database schema
- No need for CloudFront distribution
- Internal load balancer sufficient
- Publish Request Processor
- No need for CloudFront distribution nor a load balancer
- Publish Request API
-
For upload direct to S3, users will be required to have Javascript enabled.
-
For load testing, it will be necessary to identify realistic figures for concurrent users and file sizes.
- It would be useful to identify min, max and average file sizes
Prototype
A prototype of the design was put together in the following repositories and tagged:
- Frontend: https://github.com/digital-land/lpa-data-validator-frontend/tree/odp-001-prototype
- Backend: https://github.com/digital-land/async-request-backend/tree/odp-001-prototytpe
Database design
In order to make the backend re-usable for other asynchronous workloads on the platform, a generic data model has
been designed for the Request Database which should satisfy the needs for most types of request.
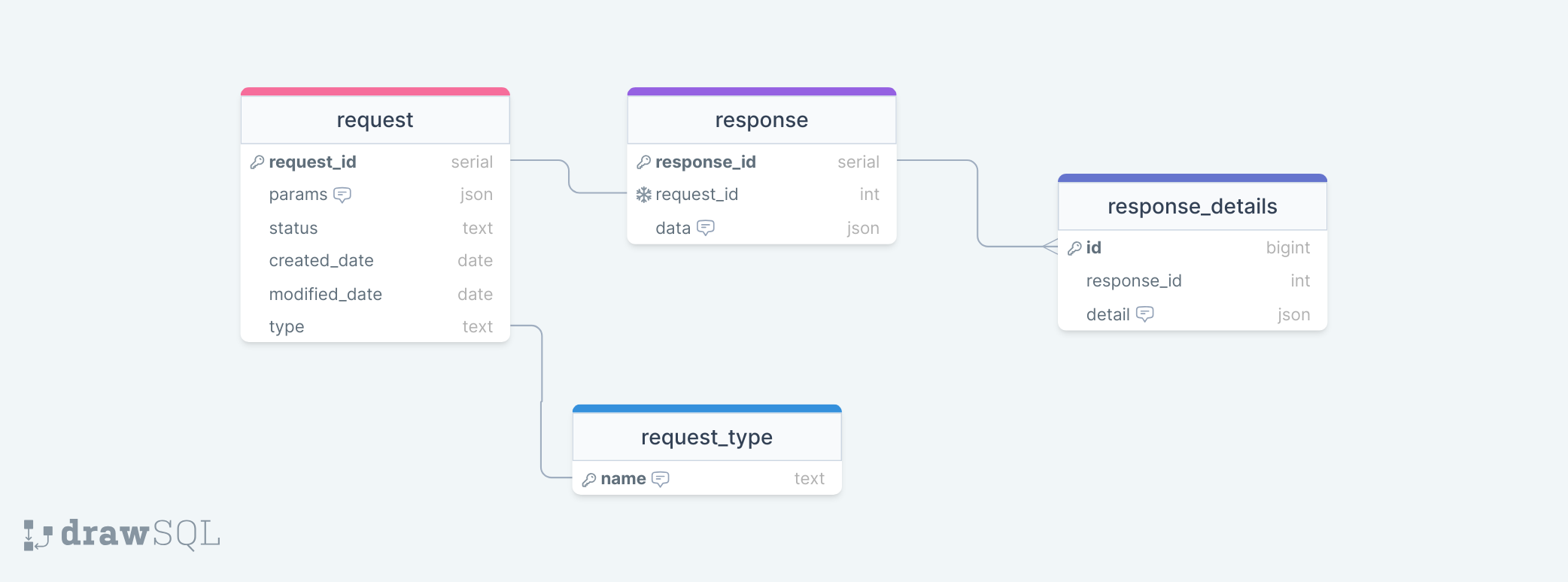
The design allows for arbitrary request parameters in JSON format and arbitrary response data, again in JSON format, at
two levels of granularity. High-level data associated with a response can be stored in the response entity while
lower-level or repeating data associated with a response can be stored in the related response_detail entity.
It is envisaged that for some request types, response data at the root level will prove
sufficient, while other request types such as datafile checks will require row-level granularity and as such can make
use of multiple response_detail entities for each row.
Design Comments/Questions
Main feedback from Owen Eveleigh was to make the Publish Request API and Processor (backend) part of the platform
system so that it can be re-used by other systems for handling large workloads asynchronously.