Weeknote—21 July 2023
Testing the specification for planning applications
Using the planning data that we were able to collect from Camden, Adur & Worthing, and Nottingham we’ve built a proof of concept index of planning applications that allows you to explore the data.
Despite just looking at a small sample of local planning authorities it was useful exercise and we’ve written up some of the things that we learnt.
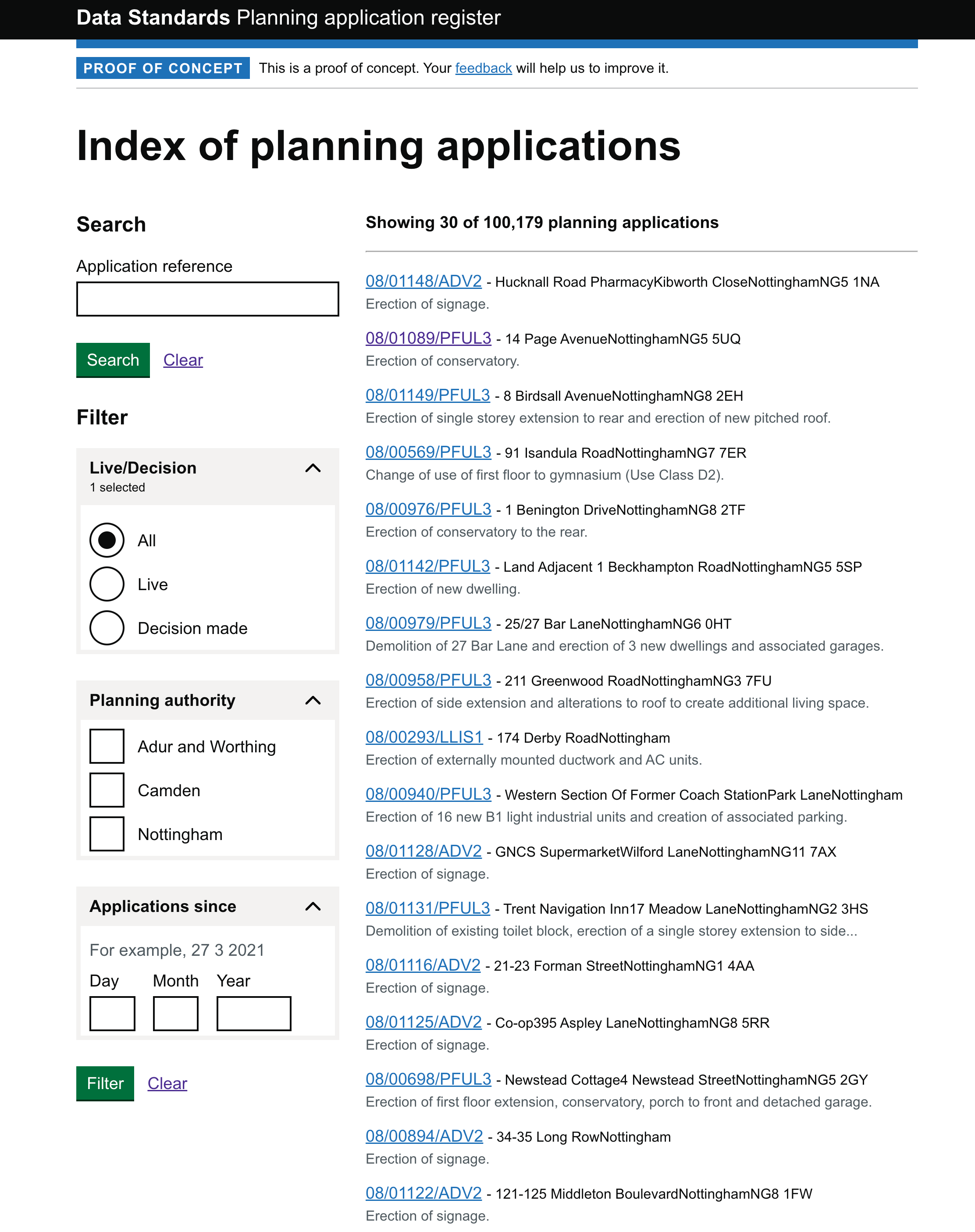
For this initial piece of work our goal was to try and collect planning application data that was already being published and to see how closely this aligned with our draft specification without the LPA having to change anything. It’s encouraging to see that the planning application records we were able to collect with relative ease. However the planning application log data had a lot of gaps, and where we do have some data this required some manual processing.
Our next steps are to play back what we’ve learnt to colleagues in planning policy as well as the LPAs we’ve been working with and to start exploring the feasibility of LPAs publishing data that more closely aligns to our draft specification.
Setting ourselves up for user testing
Using the prototype toolkit we’ve built a version of planning.data.gov.uk that we can use to more easily make changes that we can take out to test with users. This will enable us to more quickly test potential improvements and iterate the live site.
To support this, the operations research team has begun to build a research plan to understand more about the users of the platform. We’re starting with users who want to use data from the platform, understanding their needs and various ways they may want to access the data.
Service mapping
The design team are continuing to synthesise the feedback on the service map. Our next step will be to review and prioritise the problems and opportunities to make sure that we’re focused on the issues slowing down the platform operations. For example, opportunities to develop better tools and processes to speed up adding data.
Identifying erroneous data
We’ve put together an MVP tool to help the data engineers validate data endpoints before adding them to the platform. This is currently in the form of a Jupyter notebook.
This tool has already helped us identify some issues with endpoints that LPAs have requested to be added to the platform. By identifying these issues early it has stopped us from adding erroneous data to the platform. We’ll continue to iterate and improve this tool.