Data principles
Contents
To ensure consistency of data that has been provided from multiple sources, we have established a set of principles that are used across all data sets.
Structuring data
Our data models share similar principles of a relational database. This helps to reduce duplication and makes the data easier to maintain, which in turn increases the trust and usefulness of the data.
When modelling the data standard for developer contributions we created 3 files which can be linked together using unique identifiers. The first .csv contained a list of all agreements. In the second .csv we listed all the contributions, linking them back to the agreement they came from. In the third .csv we listed all the transactions and linked them to the contribution they are being paid towards.
This style of data model means that each .csv only has to contain the minimum amount of required information, but we can link to related datasets to provide context and further detail.
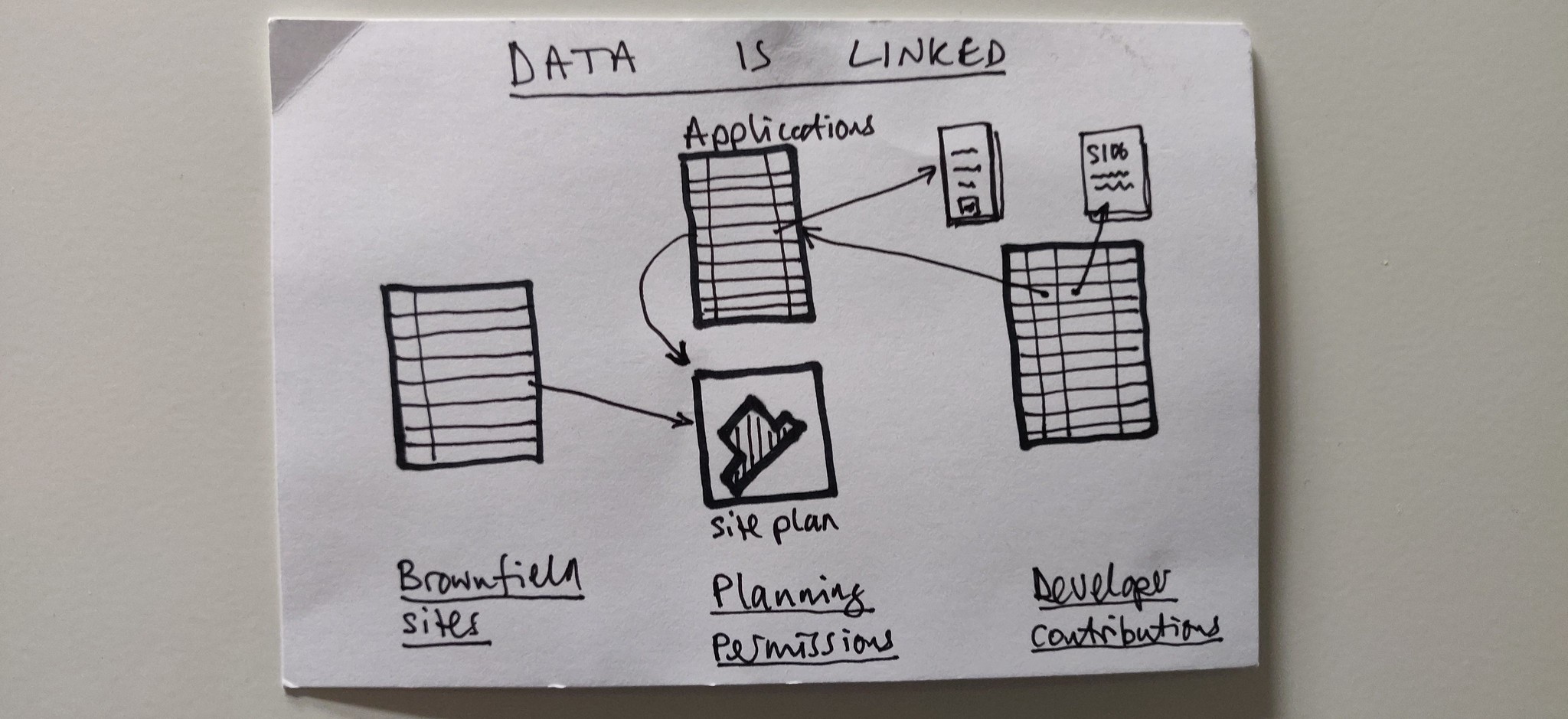
The smaller the better
The smaller the breadth of the data model, the easier it will be to maintain and publish. When datasets become too broad, it increases the chance that data will be missed out, guessed, or needed to be made non-mandatory. This is related to how we structure data.
Not deleting entries in a register
Once something changes, is superseded, or becomes redundant, a new record should be added to the register. The old one can be marked as expired through the use of an end date.
Showing any changes in data helps to make the data more trustworthy and provides reassurance. It also allows service provides to build historic views of the data to demonstrate what has changed over time.
Dates
Date format
Dates can be written in many different ways. To avoid confusion, all dates should comply with the internationally recognised ISO 8601 standard.
A date should be represented as YYYY-MM-DD, so for example, 4 June 2018 would be written as 2018-06-04.
Entry, start and end dates
Each record within a register has 3 date attributes. These describe when the record was created, when it came into effect, and from when a record was no longer active.
The dates are represented as a entry-date, a start-date, and an end-date.
As an example, in a register of countries Czechoslovak Republic became The Czech Republic on 1 January 1993. This is represented in their register as:
| official-name | start-date | end-date |
|---|---|---|
| Czechoslovak Republic | 1992-12-31 | |
| The Czech Republic | 1993-01-01 |
End dates
Once an entry is no longer valid or active, do not delete it from your register. Instead, simply add an end date. Keeping historical entries is good practice. Not only do we encourage transparency because it increases trust in the data, but seeing changes and patterns over time is useful for planning, development and policy.
IDs
Each record within a register should have a unique identifier (ID). IDs are used to string together records across multiple registers.
When creating a unique identifier you should:
- avoid the use of personal or private data in the identifier
- create an ID that will always be unique
- never reuse this ID
- assign an ID to all records
Persistent URLs
You should be able to link to a data set from a URL. It is important that overtime the URL does not change. If a URL changes then it will make finding the data more difficult and will break anything that relies on the data. Users of the data need to be able to trust that a URL will take them to the most up to date set of data.
Please make sure you send us the URL to the CSV file, rather than to the web page the CSV file sits on.
Licensing
Data should be published with clear licensing terms which state how the data can be used, and who can use it.
Where possible, data should be published under an Open Government License.
Available in a non-proprietary format
Data should be published in a format that is available without the use of proprietary software. For example, data published as .csv, .tsv or .json can be used freely, regardless of the users choice of development tools. On the other hand, data published in .xls or .pdf is locked to a particular vendor.
Easily accessible
All data should be accessible without any unnecessary requirements, such as providing an email address or credentials.
No derived or calculated data
To help ensure integrity, the data set shouldn't contain any values that can be derived or calculated from other values.
A way to feedback
When people are using the data it is important that they're able to feedback. They might have questions about the data, or they may have noticed errors. Make this easier for users by providing:
- details of who owns the data
- details of who published the data
- a way for someone to feedback